这是Hinton的第10课
这节课有两篇论文可以作为背景或者课外读物《Adaptive mixtures of local experts》和《Improving neural networks by preventing co-adaptation of feature detectors》。
一、为什么模型的结合是有帮助的
这部分将介绍为什么当我们进行预测的时候,想要将许多模型结合起来。如果我们只有一个模型,我们不得不对这个模型选择某些能力:如果我们选择的能力太少,那么模型可以在训练数据中拟合规律;而如果我们选择过多的能力,那么就有可能拟合到具体训练数据集合中的采样误差。通过使用一些模型,我们就能对拟合真实规律性和过拟合采用误差之间进行权衡。在这部分开始的时候,会展示当你对模型进行平均化的时候,你可以得到比任何单一模型更好的期望结果。而且当每个模型之间的预测有很大不同的时候这个结果是最显著的;在本部分的结尾,会介绍几种不同的方法来鼓励不同的额模型进行非常不同的预测。

就像以前我们所认为的那样,当我们的训练数据量是受约束的,那么就倾向于会过拟合。如果我们对许多不同的模型的预测结果进行平均化,那么就能减少过拟合的现象。当每个模型的预测结果有很大的不同的时候这是非常有帮助的。
对于回归来说,平方误差可以被分解成一个偏置项和一个方差项,这有助于我们分析会发生什么。如果这个模型只有很少的能力去拟合数据(欠拟合),那么偏置项会很大,它可以用来测量这个模型逼近真实函数的poorly程度;如果模型有着过多的能力去拟合具体训练数据集中的采样误差(过拟合),那么这个方差项会很大,它之所以称之为方差,是因为如果我们从同样的分布中取得同样尺寸的另一个训练数据集,我们的模型会对这个训练数据集拟合出不同的情况(因为有着不同的采样误差)。所以我们会以这种方式得到模型拟合不同训练集和的方差。
如果我们对所有模型一起进行平均化,我们所作的就是希望将这个方差给平均化掉,这个原理可以让我们使用那些有着高能力和因而具有的高方差模型。这些高能力模型通常都有着低偏置,所以我们可以通过均化来避免高方差,从而得到没有高方差但却有着低偏置的结果。

现在就来试图分析独立的模型结果和几个模型的均化的结果。在任何一个测试样本中,一些独立的预测器也许会好于一个结合的预测器(all vs 1)。但是一些不同的独立预测器在不同的样本上会有更好的结果。(个人:这里也许想表达投票机制吧)
如果这些独立的预测器之间分歧很大,那么当在测试集合上进行均化后,这个结合的预测器通常就会比所有的这些独立预测器结果要好(1 vs all)。所以我们应该关注于在没有导致更坏的预测结果的情况下,让这些独立的预测器之间产生分歧。也就是让这些独立预测器之间有着非常不同的误差,但是每个却相当准确。(个人:也就是选用不同的判别误差模型,所以有不同的误差,但是却有着差不多的很好的预测准确率。)

所以,现在来看看数学和当将这些网络结合起来会发生什么。这里是将两个期望平方误差进行对比,第一个期望平方误差是当我们随机挑选一个预测器并使用它来做的一些预测结果,第二个误差是对所有的预测器进行平均化得到的。
所以Y杠(上图Y上有一杠),是对所有的预测器的预测结果进行均化得到的,Yi是每个独立的预测器的结果。并且这里使用角括号来表示一个期望结果(个人:觉得这里角括号下的 i 没什么意义,都可以忽略的),用来表示N分之一乘以所有的Yi的和。
(上图第二行公式)如果我们观察随机选择一个预测器得到的期望平方误差,我们所要作的就是将这个预测器结果与目标进行对比,这里使用的是平方误差,然后对所有的这些预测器进行平均化,就像式子左边表示的一样。如果只是简单的加一个Y杠,并减去一个Y杠,也就是没有改变结果,就能得到式子右边比较容易处理的情况。
(上图第三行,等号和等号右边。)现在就能对第二行右边的式子进行简单的展开得到简单的类似(a^2+b^2+2ab)这样的结果。
(最后一行)对于第一项来说,因为没有涉及到 i 所以对于<>i 来说是常数,可以被分隔出来,也就是目标与组合预测器的平方误差。我们的目标是为了说明等号的左边大于右边,也就是在使用了均化后,我们可以减少期望平方误差。所以在式子的右边的额外的项就是独立预测器与均化预测器的平方期望,而这就是yi 的方差了。第三项会消失,因为yi与Y杠之间的误差是与均化预测器与目标值的误差之间是不相关的(即圆括号的项与角括号的项之间不相关),所以是有着0均值和不相关两个方面,所以会得到个0的结果,这一项就会消失。
所以结果就是通过随机挑选的一个模型的期望平方误差是大于通过均化所有模型输出的方差的平方误差的。这也就是当我们使用均化得到的有益的地方。

在这个图片中展示的就是,沿着水平线,是输出的可能值,这时候所有的不同的模型会预测出一个过高的值。
以 t 作为参考点,这些比 y杠更远的预测器会有比 均化预测器更大的平方误差,如图中红色的 bad guy,而这些比 y杠更近的预测器有着比均化预测器更小的平均平方误差。相对来说第一个会占主导地位,因为我们使用的是平方误差(明显得到的结果是大于y杠减去epilision的平方的)。所以观察上图中的式子,假设good guy和bad guy 离 y杠的距离相等,而如上图所示,得到的结果就是均化模型的平方误差加上epilision的平方,所以我们胜利的地方在于将它们与目标对比之前就进行预测器的均化。不过这也不总是正确的,这也是需要依赖于使用一个平方误差来进行测量的。
例如,你有一整群的时钟,并试图通过对它们进行均化来达到使它们更加的精确,而这将会是个灾难,因为你期望的时钟内的噪音不是高斯噪音。而你所期望的是一些时钟都是有着轻微的错误的,而少量的时钟会停止,或者甚至错的离谱。这时候如果你进行均化那么结果就是它们都会都有明显的错误,而这却不是你所期望的。
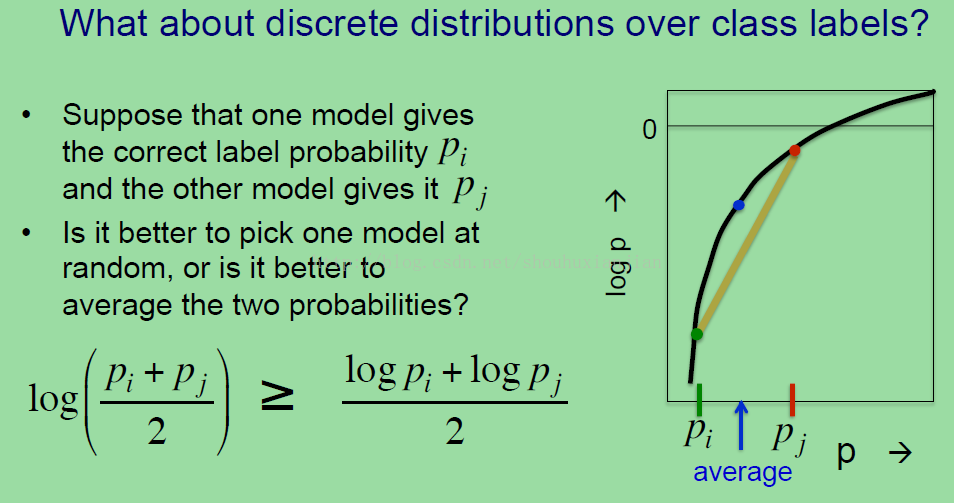
同样的事情可以应用早离散分布上,例如我们的标签概率。所以假设我们有两个模型,一个给我们pi概率的正确的标签,另一个给我们pj概率的正确标签。
是随机选择一个模型更好呢,还是对两个概率进行均化,然后预测pi和pj的均化结果更好?如果有个测量正确结果的方法是log概率,那么均化pi和pj的log会比分别对pi和pj进行log之后的均化要好,这在图中是最常见的,因为log函数的形状如上图右下角所示。所以这个黑色曲线就是log函数,在水平方向上是pi和pj的概率值,黄色的线是logpi到logpj的联合线段。这个图就可以很好的说明这个公式了(个人:其实这就是凸函数,而且很像jensen不等式,在em算法中有介绍)。
所以如上上图说是,进行均化可以得到很好的优势,我们需要我们的预测器相互之间有很大的不同,并且有许多不同的方式来形成不同。你可以只依赖于一个效果不是很好的学习算法,并且每次会陷入不同的局部最小,这不是个明智的方法,但是却值得一试。
你可以使用许多不同的模型,包括哪些不是NN的模型,所以比如决策树、高斯过程模型,SVM(Hinton说在本课程中不会讲解这些,感兴趣的就去coursera上看andrew ng的机器学习),或者其他的模型。
如果你真的想要使用一群不同的NN模型,那么你可以通过使用不同的隐藏层数、不同的每层的单元数、不同的单元类型(个人:这里只激活函数)来让它们不一样,比如一些网络中,你可以使用ReLU,而在其他的一些网络中使用逻辑函数。你可以使用权重惩罚的不同的类型或者强度,所以你可能需要对一些网络进行早期停止、其他的进行L2权重惩罚、其他的进行L1权重惩罚。你可以使用不同的学习算法。例如你可以对一些网络使用全批量学习,而其他的一些使用mini批量学习,不过这里的前提是你的数据集够小(全批量没法应对大数据,因为内存也装不下)。

你同样可以通过在不同的训练数据上训练模型来达到模型之间的不同。所以这是由Leo Breiman 引入的一种方法,叫做“bagging”,也就是数据集合的不同的子集上训练不同的模型,而这些子集是通过更换训练集合然后采样得到的,所以我们对一个有着样本为A、B、C、E、D,的训练集合进行采样,这里是五个样本,但是我们让某些样本消失掉,某些样本进行重复。然后将模型在这些具体的训练集合上训练;这种方法叫做随机森林,是通过使用有着决策树的bagging,同样也在Leo Breiman的发明中涉及到了。当你使用bagging来训练决策树的时候,然后对它们进行均化,那么效果会比它们之间的单一的决策树的效果要好得多。事实上,这些连接的盒子是使用随机森林来将深度信息转化到它们的部分实体位置信息上。
我们可以使用带有NN的bagging,但是代价很大,如果你想用这种方法训练20个不同的NN,那么你就需要到20个不同的训练集合,而且需要20倍的训练时间。这对于决策树来说没影响,因为决策树的训练够快;同样的在测试的时候,你需要运行这20个不同的网络,而同样的,对于决策树来说,它们轻松应对,因为他们在测试的时候依然很快。
另一个让训练数据不同的方法是在整个训练集合上训练每个模型,但是对每个样本的权重是不同的,所以在boosting中,我们通常使用一个相当低能力模型(个人:也叫做弱分类器)的序列(个人:也叫做级联)。然后我们对每个不同的模型在这些训练样本上有着不同的权重,我们所做的就是对之前模型分类错误的样本进行升权;而对之前模型的正确样本上进行降权。所以序列中的下一个模型不会浪费它的时间在对那些已经正确的样本上进行建模,而是专注于试图处理那些模型分类错的样本上。一个早期boosting的应用是在MNIST与NN一起使用的,而且当时的计算机计算能力是相当慢的。不过这里的一个巨大的优点就是它专注于那些基于技巧性情况上建模的竞争资源,而不一遍又一遍的浪费时间在那些容易的情况上(个人:也就是分类正确的类就直接过了,然后对那些容易模糊的类上进行斟酌)。
二、专家混合系统
在这部分将会介绍专家混合系统模型,是在1990年被提出的。这个模型的想法是先训练一些NN,每个NN在数据的不同部分都是专家。也就是说,我们假设有一个来自于不同制度(这个词为regimes在第七课中有出现,当时翻译成制度,虽然还是觉得规则比较好,直接翻译成政权肯定怪怪的)的数据集,然后我们去训练一个系统,在这个系统中每个NN在每个制度中是专业的,还有一个管理NN用来观察输入数据并且决定将数据给哪个专家。这种系统对于数据的利用来说并不高效,因为这些数据被所有的不同的NN所划分了,所以对于小数据集来说,也就不期望能够有多好的效果了;但是随着数据集合的变大,这种系统将会表现的越来越好,因为它能够极好的使用这些数据。

在boosting中,模型上的权重不是全部相等的,但是当我们完成训练后,在每个测试样本上的每个模型都具有相同的权值。我们不会让在独立模型上的权重依赖于我们所处理的具体的样本。在专家混合系统中,我们却是这么做的,所以原理就是:我们在训练和测试的时候观察输入数据中的具体样本有助于我们决定我们该依赖于哪个模型,在训练的时候可以让模型专注于这些样本的一个子集,所以它们不会去专注于那些没有被它们挑选的数据样本。所以它们可以忽略那些它们觉得不好建模的数据。这会导致独立的模型擅长于一些事物而又很不擅长其他的一些事物。
关键的原理是建立每个模型或者我们称之为专家的模型,专注于预测那些已经比其他专家擅长的样本的正确答案,这就会引起专家化。
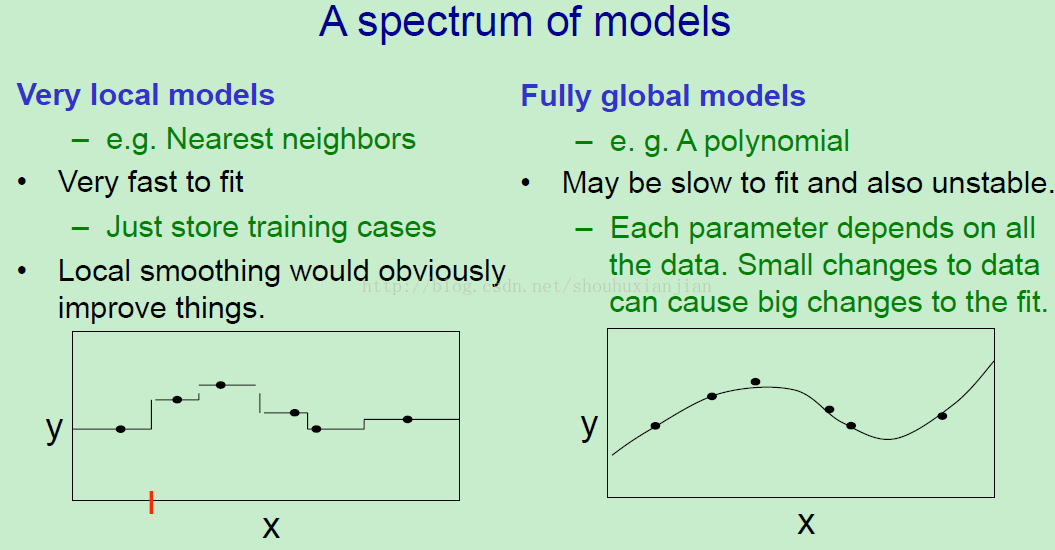
所以这里就是从非常局部的模型到非常全局的模型的模型谱。
例如,最近邻是一个非常局部的模型,为了拟合它,你只需要将训练样本存储起来,所以这是很简单的。然后如果你想从X中预测Y,你只需要简单的将存储的样本中最接近X的测试值的部分找到就行,然后Y就是这些存储的预测值。(个人:最近邻的原理可以简单的参考百度百科,想法还是很容易懂的)结果就是这个相关于输入到输出的曲线包含着许多通过悬崖连接的水平线(上图中左边那个图),很明显的需要对这个所谓的曲线进行平滑处理。
另一个极端就是我们有着充分的全局模型,就像通过一个多项式来对所有的数据进行拟合一样。我们知道拟合数据是很难的,并且很不稳定,也就是说在数据中的微小的改变会让你所拟合的模型中有着较大的改变,这是因为每个参数都是依赖于所有的数据的。

介于上上图中的模型谱的两个极端的中间,就是有着许多的局部模型,它们都有着适度的复杂性。当数据集包含着一些不同的制度,而且这些不同的制度有着不同的输入/输出关系,那么这样的情况就很好。例如在金融数据中,这些经济的状况会很大的影响着输入到输出的映射,你也许想对于不同的经济状况有着不同的模型,但是你事先却不知道如何决定是什么构成了不同的经济状况,所以你还需要去学习这部分。
所以如果我们对不同的制度使用不同的模型,那么这就有问题了,我们怎么划分数据的不同部分到这些不同的制度中呢?
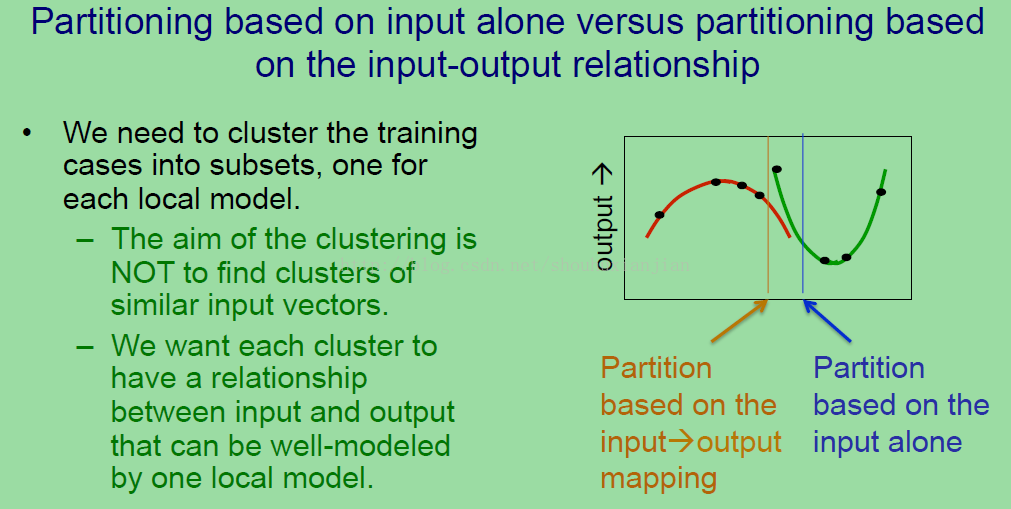
为了让不同的模型去拟合不同的制度,我们需要将训练数据聚类成不同的子集,每个对应成不同的制度,但是我们不想基于输入向量的相似性来进行数据的聚类(个人:也就是不使用k-mean的方法),我们所感兴趣的就是输入与输出之间映射的相似性。所以如果你观察上图右边的图形,那里有四个数据点被很好的用红色抛物线所拟合,另外的四个数据点被很好的用绿色抛物线所拟合。(上图中黄色文字所述及黄色竖线)如果划分数据是基于输入/输出的映射,也就是基于这样的想法,这个抛物线就能很好的拟合数据,然后你就可以通过上图中黄色线来进行划分数据;(上图中蓝色文字所述及蓝色竖线)如果你只是通过对输入数据进行聚类来划分数据,就如上图蓝色线所划分的一样,这时候如果你观察这个蓝色线的左边,你就会发现这样的一个数据子集没法很好的通过一个单一的模型来进行建模。

所以这里将会介绍一个误差函数,它能够鼓励模型之间的合作,然后介绍一个误差函数可以鼓励模型进行专家化。并试图给出个直观的理解,为什么这两个不同的函数有着非常不同的影响。
所以如果你想鼓励合作,你所需要做的就是通过将目标与所有的预测器的平均预测进行对比,然后一起训练这些预测器来减少目标与它们的输出均值之间的差异。这里再次使用角括号作为期望的标识,这个误差就是基于目标与所有预测器的输出均值之间的平方误差(上图中右边的式子)。这会严重的过拟合,并使得这些模型在分别独立训练的时候每个预测器的有着更多的能力,因为这些模型会学习弥补其他模型所造成的错误(即误差)。
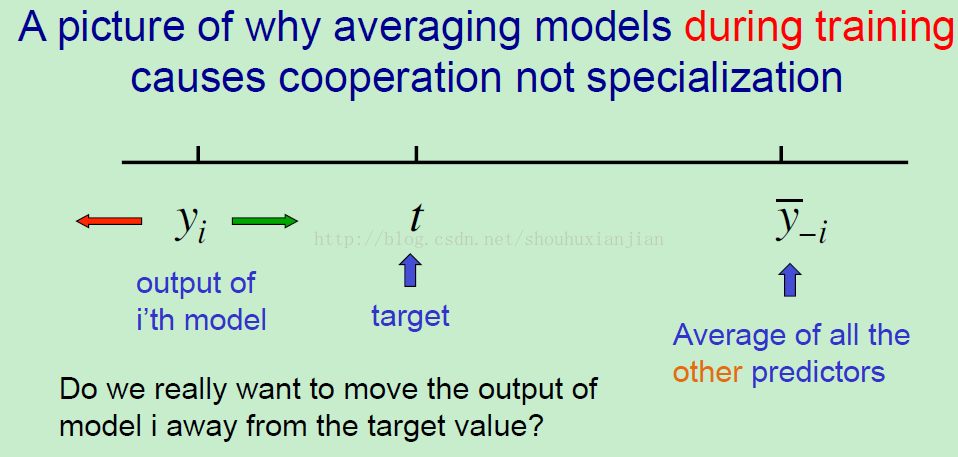
所以如果在训练的时候均化模型,并想训练使得均化能够很好的工作,你就需要像下面这样考虑这些样本了。在上图的右边,我们需要对所有除了模型 I 的其他模型进行均化,也就是均化其他模型的投票;在上图的左边,就是模型 I 的输出,现在如果我们想让总的均值能够更加的靠近目标,我们就需要对模型 I 的输出做一些事情。如果我们将模型 I 的输出远离目标(上图红色箭头),那么就会使得总的均值朝着目标移动,你会发现模型 I 是试图弥补其他模型所犯下的错误。但是我们真的需要移动模型 I 朝着错误的方向吗(正常道理应该是模型 I 的输出接近目标才是真的,所以红色箭头其实也就是朝着错误的方向前进)。直观上说,将模型 I 朝着目标移动看上去应该是更好的(上图绿色线头的方向)。

所以这里就是一个误差函数,有助于鼓励专家化,而且它不是那么不同。为了鼓励专家化,我们需要分别将每个模型的输出与目标之间进行对比。我们同样需要使用一个管理来决定每个模型上的权重,也就是认为选择某个模型的概率。
所以现在,我们的误差就是基于所有不同的模型的平方误差乘以挑选这个模型的概率的期望(上图中的公式)。这个管理或者守卫网络通过观察具体样本上的输入来决定这个概率。如果你想最小化这个误差,那么大多数的专家将会以忽略大多数的目标值告终。每个专家只会处理训练样本集合中的小子集,并且会学着在那个小子集上做的很好。
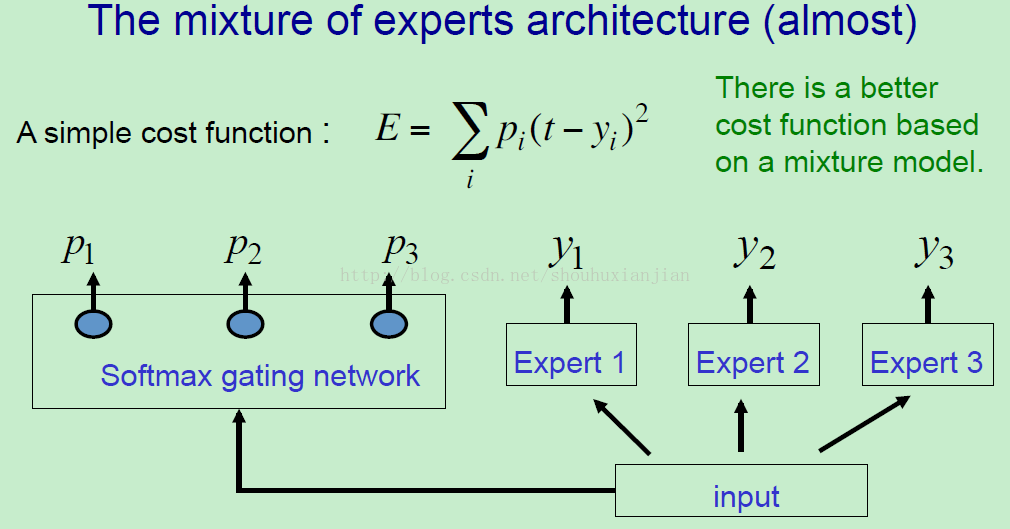
这里就是一个专家混合系统的结构。我们的代价函数就是基于均化所有的专家的基础上的目标与每个专家的输出的平方误差,但是还伴随着由管理分配的不同的权重。事实上有个基于这个混合模型的更好的代价函数,不过这是Hinton首先想到的一个代价函数,并且认为它可以更简单通过这个代价函数来解释直观的情况。
首先有个输入,所有的不同的专家都会看着这个输入,它们会基于这个输入生成它们的预测结果。另外还有个管理,这个管理会有许多层,并且这个管理的最后一层是一个softmax层,所以这个管理的输出是作为这些专家的概率的。使用这个管理的输出和专家们的输出,我们可以计算这个误差函数的值。

如果我们观察这个误差函数的导数,这个管理的输出是由输入到管理的最终层的softmax层的 xi 决定的,然后这个误差是由专家的输出决定的,同样的还有管理决定的概率输出。
如果我们对这个误差关于一个专家的输出进行求偏导,我们会得到训练这个专家的一个信号,而且得到的这个梯度就是挑选这个专家的概率乘以专家与目标值之间的差异(上图第二个的那个求导的式子)。所以如果管理给出这个专家对于具体的训练样本有个非常低的挑选概率,那么这个专家将会得到一个非常小的梯度,并且在这个专家内部的参数不会被这个训练样本所打扰。那么就可以保留它的参数 ,然后对很大概率的训练样本集进行建模。
我们同样对关于这个守卫网络的输出进行求导,并且事实上我们所要做的就是求关于softmax层输入的导数,也就是关于 xi 的导数(上图最下面的式子)。如果我们求关于 xi 的导数,也就是挑选专家的概率乘以介于目标函数和这个专家输出的平方误差与均化总的专家之间的差异(上面最下面的式子的右边)。当你使用这个由平方误差的管理提供的权重,也就是如果专家 I 有着比其他专家的均化值更低的平方误差,那么我们就会提升专家 I 的概率;但是如果专家 I 有着比其他专家更高的平方误差,我们就试图降低它的概率。这也就是所谓的专家化。

现在介绍这个事实上更好的代价函数,它只是更加的复杂。它依赖于混合模型,也就是前面的课程中没介绍过的。再次提及,这个可以在andrew ng 的课程中找到。
然而,当做回归的时候,并且将网络视为是做高斯预测的时候已经解释过最大似然的概念了。也就是网络输出一个特定的值,y1,然后我们认为这是一个赌注关于当在Y1的周围有着单位方差的高斯分布上目标值应该是多少。所以上图中的红色专家是做一个在y1 周围的高斯分布预测,这个绿色专家是做一个关于y2 周围的预测。
这个管理随后决定这两个专家的概率,这些概率是用来缩小这些高斯的。这些概率需要加起来,而且他们称之为混合比例。所以一旦我们缩小了这些高斯,我们就得到一个不是高斯的分布,而是缩小的红色高斯和缩小的绿色高斯的和。这就是来自专家混合系统的预测分布。
我们现在要做的就是最大化这个在黑色曲线上目标值的log概率(这里的黑色曲线只是红色曲线和绿色曲线的和)。

上图就是得到的在给定专家混合系统上概率重目标的模型。这里的概率就是式子的左边部分,就是等于式子的右边部分。所以我们的代价函数是简单的变成了左边概率的负log,并试图最小化这个概率的负log。
三、全贝叶斯学习的原理
在这部分,将回到上一课中的全贝叶斯学习,并解释它如何工作的,并在随后的部分中介绍如何让它能够实际运用起来。

在全贝叶斯学习中,我们不是只是简单的去寻找一个的参数的最好设置(setting)集合,相反的,我们试图去找到基于所有可能的设置的全后验分布,也就是说,对于所有可能的设置,我们都想要一个后验概率密度。对于所有的这些密度来说,我们希望能加到一起。这是极度密集型的计算:去计算所有的部分但是却最简单的模型。所以在更早的例子中,我们采用了一个硬币例子,其中只涉及到一个参数,也就是它的偏置是多少。但是通常来说,对于NN来说,这是不可能的。
在我们计算介于所有的可能的参数设置下的后验分布,我们可以通过让每个不同的参数设置预测自己的结果来进行最后的预测,然后对所有这些预测进行均化,并通过他们的后验概率来加权。这也通常是非常密集型计算的。这样做的一个好处就是如果我们使用全贝叶斯学习,我们可以甚至在当没有很多数据的时候使用复杂的模型。

所以这里有一个非常有趣的哲学观点。我们这里使用过拟合的想法,即当使用一个复杂的模型去拟合少量的数据,但是这基本上只是一个无关于基于这些参数得到的全后验分布的结果。所以频率学派的人认为如果你没有很多数据的话,你应该使用一个采样模型。这是正确的,但是这也只当你假设拟合一个模型意味着寻找的参数的单一最好设置时候才是正确的。
如果你找到了全后验分布,那么就可以摆脱过拟合了。如果只有少量的数据,这个全后验分布通常会给出一个非常模糊的预测结果,因为许多不同的参数设置会生成非常不同的有着明显后验概率的预测结果。随着你得到更多的数据,这个后验概率会给出越来越多的关注于小部分的参数设置,并且这些后验预测结果会更清晰。
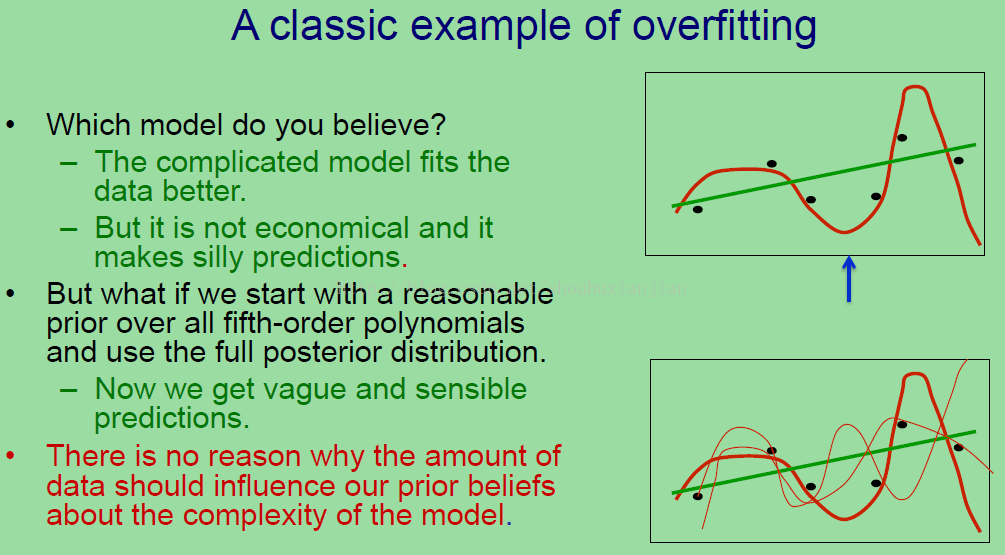
这里就是一个典型的过拟合的例子。我们有6个数据点,并通过5次多项式来拟合,结果就是这个模型可以精确的通过这些数据。我们同样画一个笔直的直线,它只有两个自由度,那么哪个模型更可信呢,是这个有着6个系数的还是有着2个系数的。很显然的这个复杂的模型拟合的更好,但是却不可信,而且会有着很糟糕的预测能力。所以如果你看上图右边第一个的蓝色箭头,如果这是输入值,你试图预测它的输出值,这个红色曲线会预测出比任何其他观测值还要低的结果,看上去很疯狂,因而这个绿线会预测出一个有意义的值。
但是任何事情都会改变,如果不是用一个5次的多项式来拟合,我们以一个合理的5次多项式的先验作为开始,例如这个系数不应该很大,然后我们基于这个5次多项式计算全后验分布。上图中显示的是一些从这个分布得到的例子(上图第二个图),这里的粗线表示在后验中有着更高的概率,所以也能看到许多细线,它们遗失了一些数据点,但是不管怎样,他们都接近于大部分数据点。现在我们得到了更加模糊但是却更有意义的预测值,所以对照之前的那个蓝色箭头部分,不同的模型预测的非常不同的结果。然而均化一下,得到的结果就相当接近于绿线所做的预测结果。
从一个贝叶斯角度出发,没有原因为什么这些你收集的数据应该影响你的先验置信和模型的复杂程度,一个真正的贝叶斯学者会说,你有关于事物复杂程度的先验置信,只是你没有收集到任何数据罢了,这不意味着你认为事情会更简单。

所以我们可以通过NN来逼近全贝叶斯学习,如果这个NN只有很少的参数的话。原理就是在参数空间中放上一个网格,所以每个参数只允许少量的回归价值(allowed a few return to values),然后我们在基于所有参数的所有值上进行交叉乘积。现在我们得到了在参数空间中的一些网格点。每个点中,我们可以看见我们的模型对预测数据的程度,也就是如果我们使用有监督学习,一个模型预测目标输出的程度。我们可以说在网格点上的后验分布是预测数据的程度、在先验中的相似程度的积。随着整个的归一化,所以这个后验概率是小于 1 的。这仍然代价高昂,但是注意到它有许多吸引人的特性:没有涉及到任何的梯度下降,没有局部最优的问题。我们不是在这个空间中跟随一条路径,我们只是评估这个空间中的点集合。一旦我们决定将后验概率指派到每个网格点上,我们就可以在测试数据上使用所有的点去进行预测。这仍然代价高昂,但是当没有很多数据的时候,它的效果要比最大似然(ML)或者最大后验(MAP)要好。
所以我们预测在给定测试输入的情况下测试输出的方法,也就是基于给定测试输入的情况下计算测试输出的概率(上图中最下面的式子的左边)等于给定数据上网格点的概率乘以给定测试输入和网格的测试输出的概率的所有的和。换句话说,我们得考虑到这个事实,我们会在给出测试结果之前增加噪音到这个网络的输出部分。

这里就是一个全贝叶斯学习的图。这里我们只有很少的网络,即四个权重两个偏置。如果可以的话,对于每个权重和偏置来说,有9个可能的值,也就是在参数空间中有9^6个网格点,这是一个很大的数值,不过我们还能应对。
对于每个网格点,我们计算在所有训练样本观察到的输出的概率。
我们通过每个网格点的先验(也许依赖于权重的值)进行相乘,然后重新归一化得到基于所有网格点的后验概率。
然后我们通过使用这些网格点来进行预测,但是通过它的后验概率来对每个预测结果进行加权。
四、让全贝叶斯学习更实用
在这部分,会介绍如何对于有着千百万的权重的NN来说,让全贝叶斯更实用,这种技术叫做Monte Carlo方法,当第一次听到这个词的时候会觉得很奇怪的方法。我们使用随机数生成器来在我们的代价函数中让权重向量空间以一种随机的方式移动,但是偏置却是下山的方式。如果我们做的正确的话,我们就得到一个很漂亮的特性,我们按比例采样权重向量到它们的后验概率上,也就是说通过采样许多权重向量,我们可以得到一个很好的全贝叶斯方法的逼近。

网格点的数目是按照参数的数目呈指数增长的,所以我们不能通过网格的方法来处理超过少量参数的情况(也就是参数超过一定情况,就没法处理了)。
如果有足够的数据让大多数的参数向量都不相似,只有微小部分的网格点会对预测有着明显的贡献。所以也许你可以只关注与评估这些我们能够找到的微小的部分。
一个让贝叶斯学习更灵活的方法是它足够好的能够按照它们的后验概率进行权重向量采样。所以如果观察上图中的式子,我们指派给一个在给定测试样本的输入和训练数据的情况下测试输出的概率(式子左边)等于右边(上图式子右侧)。现在不使用将所有的项相加的方法,我们只是从这个和 中进行项的采样,我们要做的就是按比例进行权重向量到概率的采样。所以不论我们是否采样他们,他们都会得到一个权重为1 或者为0,但是这个概率会得到 1,也就是被采样的概率会是它们的后验概率,所以这会让我们对于式子的右边部分得到正确的期望值,它没有噪音是因为虽然是采样但是却是正确的期望值。

上图是关于标准BP中的过程。在上图的右边是一个权重空间,有着很高的维度和无边界,虽然这个图看起来很糟糕,不过这也是Hinton的最大努力了。在这个权重空间中,画了一些轮廓用来表示代价函数的等值轮廓(比如地理的等高线一样)。这里使用通常BP的方法,以很小的值作为权重的初始化,然后随着这个梯度,在代价函数中进行下山式的移动,在这个方向上对于所有的训练样本来说,log似然加上log先验的和是增长的。
最后,我们会在一个局部最小值或者停留在平原上,或者只是因为移动的很慢而没有耐心等待这三种情况作为结束,但是上图中主要的观点是我们随着初始点到某些最终,单一点的路径。

现在如果我们使用一个采样方法,我们要做的就是以上上图中同样的空间作为开始,但是每次都会更新一次所有的权值,并加上一些高斯噪音。那么权重向量从来不会稳定下来它会一直保持周围移动,它会游走于这个空间,但是总是会朝着最低代价区域移动,也就是它倾向于下山。
不论我们是否能够说些什么关于权重在那个空间访问每个节点的频率上,这是一个重要的问题。所以上图中红点表示当我们游走于这个空间的时候,考虑权重的采样。想法就是我们也许可以每1000步进行保留权重的操作。如果你观察这些红点,少量红点在高代价区域,因为这些区域实在是很大,最深的最小值有着最多的红点,其他的最小值同样也有红点,这些红点不再最小值的底部是因为它们是噪音采样的。

如果我们以正确的方式加入了高斯噪音,那么这就是一个MCMC的美好的特性。这是一个令人着迷的事实。如果我们游走的足够长,那么这些权重向量将会是基于权重因子的真实后验分布上的无偏采样,也就是说,我们在上上图中看到的红点将会是从后验采样得到的,这里的权重向量都是在后验的情况下具有高可能(极高的概率)的,更像是通过红点而不是那些高不可能(极低的概率)权重因子表现出来的。这被称之为马尔可夫链蒙特卡罗(MCMC),可以使得在上千的参数上更灵活的使用贝叶斯学习。
这里推荐的增加一些高斯噪音的方法叫做???(听不清,字幕也说听不清)方法,这不是最有效的方法,有着比这更成熟而且更有效的方法,这里说的更有效是它们不需要游走在权重空间中,直到开始达到这些红点的采样部分。

全贝叶斯学习实际上可以用mini批量的方法完成。当我们在 一个随机mini批量的代价函数上计算梯度的时候,我们会得到一个带着采样噪音的无偏估计,想法就是使用采样噪音提供的噪音刚好是MCMC需要的,这是一个非常聪明的想法。
近来,Welling和他的团队让它更好的工作了,所以他们可以相当的高效的从基于权重上后验分布上使用mini批量来进行采样。这可以让使用全贝叶斯学习在更大的网络上成为可能,这里的网络是你不得不使用mini批量来训练它们从而有着更多的希望去结束训练它们。
五、dropout
在这部分上,会介绍一个在非常大数量的NN模型上训练的新的方法,该方法不需要将这些模型进行独立的训练,这个方法叫做dropout,也就是近年来在一些比赛中成功应用的方法。对于每个训练样本,我们随机忽略一些隐藏单元,碎语对于每个训练样本来说,都有着一个不同的结构,我们可以认为这是对每个训练样本都有一个同步的模型,那么问题来了,我们怎样在只有一个样本上训练一个模型,然后如何在测试的时候高校的均化所有的这些模型。答案就是我们使用大量的权重共享的方法。

这里先介绍两个不同的结合多模型输出的方法。在混合模型中,我们通过均化他们的输出概率来结合模型,所以如果模型A指派的概率为0.3、0.2、0.5到三个不同的结果上,模型B指派的概率为0.1、0.8、0.1.,这个结合的模型就是简单的将这些概率进行均化(上图左边的部分)。
另一个不同的结合模型的方法就是使用概率的乘积,这里使用的是基于同样概率上的几何均值,在与上面一样的模型和概率的情况下,通过将每对概率进行相乘,然后进行开根,这也就是几何均值,几何均值加起来的结果将会小于1.所以我们不得不进行归一化,也就是除以这几个组合后的几何均值的和,这样它们加起来就等于1了。你可能已经注意到在乘积方法中(一个模型有着很小的概率输出),有着在其他模型上投票的能力。
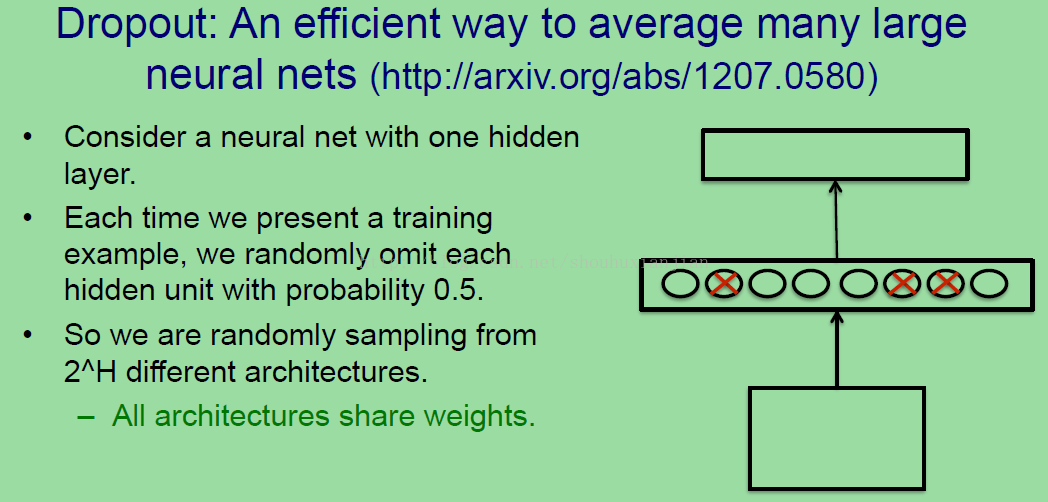
现在想要介绍一种高效的方法去均化大量的NN,这是一种代替正确贝叶斯的方法。这个可选的方法可续不能像正确的贝叶斯那样得到很好的结果,但是它却更实用。所以考虑一个只有一层隐藏层的NN(上图右边的网络),每一次我们输送一个训练样本到这个结构中,然后以0.5的概率随机忽略隐藏层中的隐藏单元,所以这里就相当于剔除了三个隐藏单元,我们运行这个样本通过NN的时候是让这几个隐藏单元缺席的,意思就是我们从2^H个不同的结构中随机采样,这里的h就是隐藏单元的个数,可以看得出来这是一个巨大的数字。当然所有的这些结构共享权重,也就是但我们使用一个隐藏单元的时候,它得到的权重与其他结构中是一样的。

所以我们可以认为dropout是模型均化的一种形式。我们从2^H个模型中进行采样,事实上大多数的模型将不会被采样到,而且这些采样到的模型也只得到了一个训练样本。这是对于bagging来说是极端的存在。这个训练集合对于这些不同的模型来说是非常不同的,但是他们同样很小
基于所有模型的权重共享意味着每个模型是被其他模型强烈正则化的,而且这是一个比L2或者L2这样的惩罚更好的正则化器,这些L2或者L2惩罚会将权重推向0.但是与其他模型的共享权重来说,是从那些倾向于将权重拉向正确值的正则化模型

仍然还有遗留的问题,我们在测试的时候该怎么做。所以我们采样许多不同的结构,也许是100,然后在输出分布的时候使用几何均值的方法,但是这需要大量的工作。应该有更简单的方法的。我们使用所有的这些隐藏单元,但是我们将它们的输出权值减小一半(训练的时候是忽略一部分隐藏单元,这里是对所有的权重乘以1/2),所以它们也有与采样时所做的同一样的期望了.结果显示使用了所有的隐藏单元的一半权重的值。假设我们使用一个softmax输出分组,那么就能准确计算所有的2^H个模型都可以用到的几何均值。

如果我们有不止一层隐藏层,我们可以简单的在每一层将dropout设置成0.5.在测试的时候,我们对所有的隐藏单元的输出权重进行一半的缩放,这也就是被称之为均值网络。所以我们使用一个虽然有所有的单元但是却只有一半值的权重的网络。当我们有着许多隐藏层的时候,这不准确的等于均化所有每个模型单一设置dropout的网络模型们,但是这是一个很好的逼近,而且很快。
我们可以运行许多带有dropout的随机模型,然后进行这些随机模型的交叉均化。在基于均值网络来说有个优势,它可以给出答案中不确定的结果。

那么对于输入层来说呢,我们可以使用同样的技巧。我们在输入上使用dropout,但是我们使用一个更高概率来保持一个输入单元。这个技巧在被称为消噪自动编码器系统中已经使用了,是由pascal Vincent、 Hugo Laracholle 和 Yoshua bengio在Montreal大学中提出的,它效果很好。

那么dropout工作效果多好呢?由Alex Krizhevsky(第五课)提出的打破对象识别记录的网络是没有使用dropout的,但是在使用dropout之后再次打破纪录。通常来说,如果你有一个DNN,而且它是过拟合的,dropout通常可以减少很大程度上的误差。Hinton认为任何需要早期停止来阻止过拟合的网络都可以使用dropout。当然更长的训练可以均化更多的隐藏单元。
如果你得到了一个DNN,而它没有过拟合,你应该可能使用一个更大的网络,然后在使用dropout,这假设你有足够的计算能力(说的是电脑的配置)

这里是另外一种方法来解释droout,也是Hinton最初认为的。你可以发现它像专家混合系统,当所有的专家都合作的时候就是错误的时候,是什么来组织专家化?所以如果一个隐藏单元知道其他那些隐藏单元是存在的,它可以与这些隐藏单元在训练数据上进行共同适应(co-adapt),意思就是真正训练一个隐藏单元的信号是试图弥补其他隐藏单元做出的结果之后的产生的误差,这也是BP训练每个隐藏单元的权重。现在这会导致隐藏单元之间的共同适应,而且这当在数据中有改变的时候看上去是错的。所以对于一个新的测试数据,如果你依赖于一个复杂的共同适应去使得在训练数据上让事情正确起来,那么就相当于在新的测试数据上工作的不是那么好,它就像一个大的、复杂的涉及到许多人的阴谋,几乎可以确定是错的,因为事情总是不是像你想的那样,如果涉及到大量的人们,他们中的一个将会以非期望的方法做出行动,然后其他的人将会做错的事。如果你想要达成一个阴谋那么结果会更好,得到许多的微小的阴谋。那么当非期望的事情发生的时候,许多的微小阴谋就会失效,但是还有一部分将会成功。
所以通过使用dropout,我们强制一个隐藏单元是与其他隐藏单元集合合作的,这就像是做一些独立有用的事情而不是只是一个有用的事情,因为其他具体的隐藏单元都是合作的。但是这仍然倾向于某些独立有用的事情,并且不同于其他隐藏单元所作的。它需要某些轻微有用的事情(个人:这意思应该也是弱工作人员,通过所有的合作达到一个强结果吧),通过给定合作的工人一起去达到。这就是为什么在给一个网络执行dropout的时候它们表现出很好的性能。